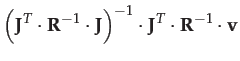Next: 3 Assuring Convergence Up: Gauss-Newton / Levenberg-Marquardt Optimization Previous: 1.4 Objective Function
We approximate
![]() as a function of
as a function of
![]() by
a first-order Taylor expansion:
by
a first-order Taylor expansion:
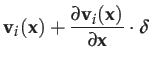 |
|||
This approximation then extends trivially to the whole error vector:
| (22) |
Substituting this approximation into :autorefequation19 yields
| (23) |
To minimize this residual, we differentiate with respect to
![]() ,
set equal to zero, and solve for
,
set equal to zero, and solve for
![]() :
:
The Fisher information matrix
![]() is symmetric and positive definite, so the linear system can be efficiently
solved with a Cholesky or
is symmetric and positive definite, so the linear system can be efficiently
solved with a Cholesky or
![]() decomposition. Further,
if the observations are independent, the information matrix and information
vector are simply accumulated over the observations:
decomposition. Further,
if the observations are independent, the information matrix and information
vector are simply accumulated over the observations:
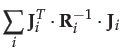 |
(29) | ||
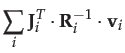 |
(30) |
The update from Eq. :autorefequation31 is then applied by pertubring
![]() by
by
![]() :
:
The whole process is iterated by evaluating
![]() and
and
![]() at the new parameters, recomputing
at the new parameters, recomputing
![]() (Eq. :autorefequation28),
and applying the update (Eq. :autorefequation31). The iteration continues
until some convergence criterion is met, or the iteration count reaches
a bound.
(Eq. :autorefequation28),
and applying the update (Eq. :autorefequation31). The iteration continues
until some convergence criterion is met, or the iteration count reaches
a bound.
Note that upon convergence to a minimum of the residual,
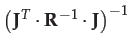 (the inverse of the information matrix) is the Cramer-Rao lower bound
for the covariance of the parameters.
(the inverse of the information matrix) is the Cramer-Rao lower bound
for the covariance of the parameters.
Ethan Eade 2012-02-16