Next: 3.2 Levenberg-Marquardt Method Up: 3 Assuring Convergence Previous: 3 Assuring Convergence
Define a modified information matrix, with a damping factor ![]() :
:
| (32) |
As
![]() ,
,
![]() approaches the unmodified
information matrix. For
approaches the unmodified
information matrix. For
![]() ,
,
![]() is dominated by the identity matrix. As
is dominated by the identity matrix. As ![]() increases, the
computed update
increases, the
computed update
![]() tends to the scaled
gradient descent direction:
tends to the scaled
gradient descent direction:
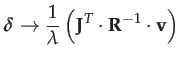 |
(33) |
To control convergence behavior, we modify ![]() according to
a simple schedule, controlled by two factors
according to
a simple schedule, controlled by two factors ![]() . Typical values
are
. Typical values
are ![]() and
and ![]() . Starting with parameters
. Starting with parameters
![]() , residual
, residual
![]() , and damping value
, and damping value ![]() , an update
, an update
![]() is computed and applied:
is computed and applied:
| (34) |
Then the residual
![]() is computed under the
new parameters. If the residual has decreased, such that
is computed under the
new parameters. If the residual has decreased, such that
![]() ,
then the update is valid, and the damping factor is decreased by factor
,
then the update is valid, and the damping factor is decreased by factor
![]() :
:
| (35) | |||
| (36) |
If the residual has increased, or has not decreased by some threshold
amount, the parameters are left unchanged and ![]() is increased:
is increased:
| (37) |
Thus only parameter updates that decrease the residual are kept. The
process is iterated similarly to the Gauss-Newton method, and can
be terminated when ![]() reaches a large threshold value (which
corresponds to a vanishingly small update). Note that in the case
where the parameter update is rejected and
reaches a large threshold value (which
corresponds to a vanishingly small update). Note that in the case
where the parameter update is rejected and ![]() increases, the
information matrix and vector need not be recomputed. Instead only
the matrix
increases, the
information matrix and vector need not be recomputed. Instead only
the matrix
![]() needs to be updated using the new
needs to be updated using the new ![]() value, and the linear system solved to find a new
value, and the linear system solved to find a new
![]() .
.
Ethan Eade 2012-02-16