Next: 4 References Up: 3 Assuring Convergence Previous: 3.1 Levenberg Method
A refinement due to Marquardt changes how
![]() is defined
in terms of
is defined
in terms of ![]() . Instead of damping all parameter dimensions
equally (by adding a multiple of the identity matrix), a scaled version
of of the diagonal of the information matrix itself can be added:
. Instead of damping all parameter dimensions
equally (by adding a multiple of the identity matrix), a scaled version
of of the diagonal of the information matrix itself can be added:
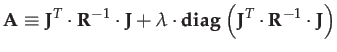 |
(38) |
As ![]() grows,
grows,
![]() again tends
towards a gradient descent update, but with each dimension scaled
according to the diagonal of the information matrix. This can lead
to faster convergence than the Levenberg damping term when some dimensions
of the error surface have much different curvature than others.
again tends
towards a gradient descent update, but with each dimension scaled
according to the diagonal of the information matrix. This can lead
to faster convergence than the Levenberg damping term when some dimensions
of the error surface have much different curvature than others.